Features¶
The Features class is used when creating custom features.
Additionally it contains all common methods used by all features.
The most common arguments to Features are:
list_of_feature_functions = [example_feature]
features = un.Features(new_features=list_of_feature_functions,
features_to_run=["example_feature"],
preprocess=example_preprocess,
interpolate=["example_feature"])
new_features is a list of Python functions that each calculates a
specific feature,
whereas features_to_run tells which of the features to
perform uncertainty quantification of.
If nothing is specified, the uncertainty quantification is by default performed
on all features (features_to_run="all").
preprocess() requires a Python function
that performs common calculations for all features.
interpolate is a list of features that must be interpolated.
As with models,
Uncertainpy automatically interpolates the output of such features
to a regular form.
Below we first go into details on the requirements of a feature function,
and then the requirements of a preprocess function.
Feature functions¶
A specific feature is given as a Python function. The outline of such a feature function is:
def example_feature(time, values, info):
# Calculate the feature using time, values and info.
# Return the feature times and values.
return time_feature, values_feature
Feature functions have the following requirements:
- Input.
The feature function takes the objects returned by the
model function as input, except in the case when a
preprocessfunction is used (see below). In that case, the feature function instead takes the objects returned by thepreprocessfunction as inputpreprocessis normally not used. - Feature calculation.
The feature function calculates the value of a feature from the data
given in
time,valuesand optionalinfoobjects. As previously mentioned, in all built-in features in Uncertainpy,infois a dictionary containing required information as key-value pairs. - Output.
The feature function must return two objects:
- Feature time (
time_feature). The time (or equivalent) of the feature. We can returnNoneinstead for features where it is not relevant. - Feature values (
values_feature). The result of the feature calculation. As for the model output, the feature results must be regular, or able to be interpolated. If there are no feature results for a specific model evaluation (e.g., if the feature was spike width and there was no spike), the feature function can returnNone. The specific feature evaluation is then discarded in the uncertainty calculations.
- Feature time (
As with models,
we can as a shortcut give a list of feature functions as the
feature argument in UncertaintyQuantification,
instead of first having to create a Features instance.
Feature preprocessing¶
Some of the calculations needed to quantify features may overlap between
different features.
One example is finding the spike times from a voltage trace.
The preprocess function is used to avoid having to perform the
same calculations several times.
An example outline of a preprocess function is:
def preprocess(time, values, info):
# Perform all common feature calculations using time,
# values, and info returned by the model function.
# Return the preprocessed model output and info.
return time_preprocessed, values_preprocessed, info
The requirements for a preprocess function are:
- Input.
A
preprocessfunction takes the objects returned by the model function as input. - Preprocesssing.
The model output
time,values, and additionalinfoobjects are used to perform all preprocess calculations. - Output.
The
preprocessfunction can return any number of objects as output. The returned preprocess objects are used as input arguments to the feature functions, so the two must be compatible.
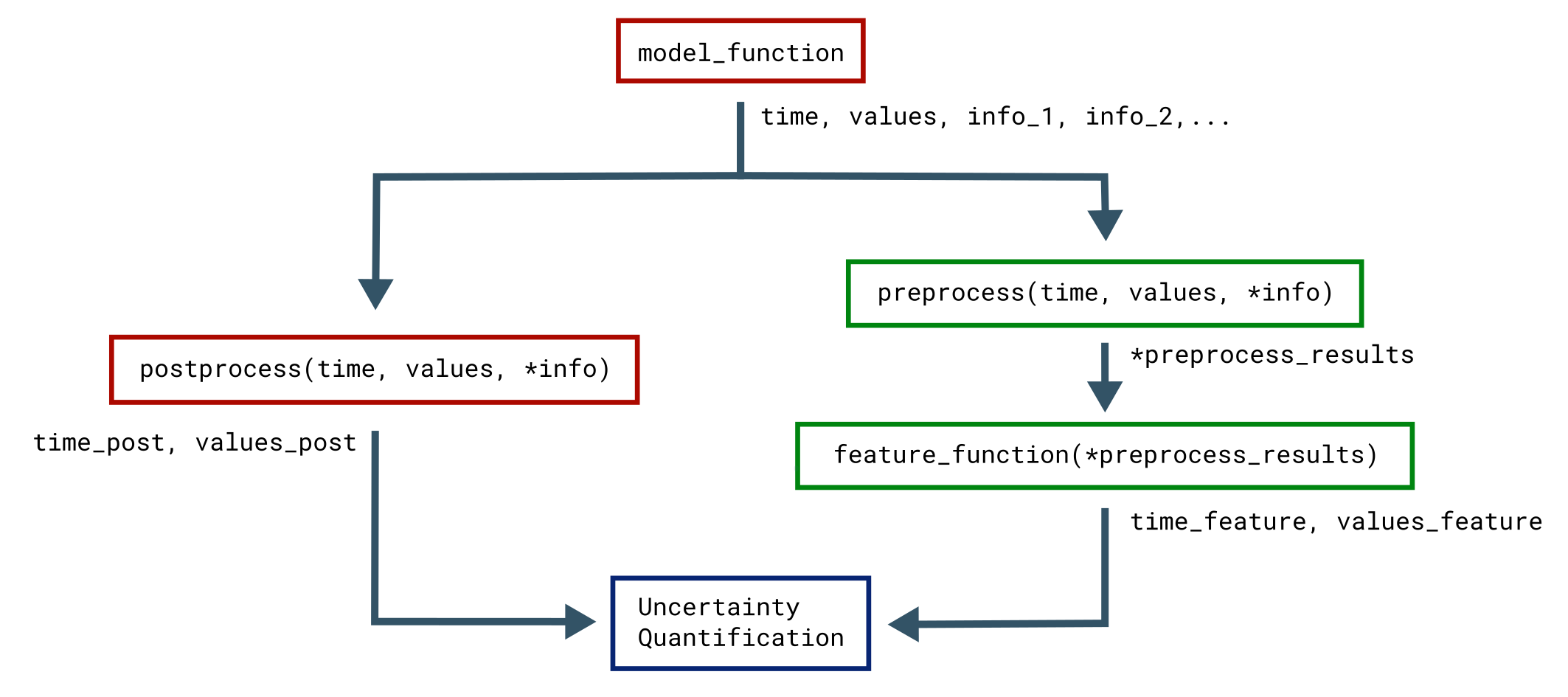
This figure illustrates how the objects returned by the model function
are passed to preprocess,
and the returned preprocess objects are used as input arguments in all
feature functions.
Functions associated with the model are in red while functions
associated with features are in green.
The preprocessing makes it so feature functions have different required input
arguments depending on the feature class they are added to.
As mentioned earlier,
Uncertainpy comes with three built-in feature classes.
These classes all take the new_features argument,
so custom features can be added to each set of features.
These feature classes perform a preprocessing, and therefore have different
requirements for the input arguments of new feature functions.
Additionally, certain features require specific keys to be present in the
info dictionary.
Each class has a reference_feature method that states
the requirements for feature functions of that class in its docstring.
API Reference¶
-
class
uncertainpy.features.Features(new_features=None, features_to_run=u'all', new_utility_methods=None, interpolate=None, labels={}, preprocess=None, logger_level=u'info')[source]¶ Class for calculating features of a model.
Parameters: new_features ({None, callable, list of callables}) – The new features to add. The feature functions have the requirements stated in
reference_feature. If None, no features are added. Default is None.features_to_run ({“all”, None, str, list of feature names}, optional) – Which features to calculate uncertainties for. If
"all", the uncertainties are calculated for all implemented and assigned features. If None, or an empty list[], no features are calculated. If str, only that feature is calculated. If list of feature names, all the listed features are calculated. Default is"all".new_utility_methods ({None, list}, optional) – A list of new utility methods. All methods in this class that is not in the list of utility methods, is considered to be a feature. Default is None.
interpolate ({None, “all”, str, list of feature names}, optional) – Which features are irregular, meaning they have a varying number of time points between evaluations. An interpolation is performed on each irregular feature to create regular results. If
"all", all features are interpolated. If None, or an empty list, no features are interpolated. If str, only that feature is interpolated. If list of feature names, all listed features are interpolated. Default is None.labels (dictionary, optional) – A dictionary with key as the feature name and the value as a list of labels for each axis. The number of elements in the list corresponds to the dimension of the feature. Example:
new_labels = {"0d_feature": ["x-axis"], "1d_feature": ["x-axis", "y-axis"], "2d_feature": ["x-axis", "y-axis", "z-axis"] }
logger_level ({“info”, “debug”, “warning”, “error”, “critical”, None}, optional) – Set the threshold for the logging level. Logging messages less severe than this level is ignored. If None, no logging is performed. Default logger level is “info”.
Variables: - features_to_run (list) – Which features to calculate uncertainties for.
- interpolate (list) – A list of irregular features to be interpolated.
- utility_methods (list) – A list of all utility methods implemented. All methods in this class that is not in the list of utility methods is considered to be a feature.
- labels (dictionary) – Labels for the axes of each feature, used when plotting.
See also
uncertainpy.features.Features.reference_feature- reference_feature showing the requirements of a feature function.
-
add_features(new_features, labels={})[source]¶ Add new features.
Parameters: new_features ({callable, list of callables}) – The new features to add. The feature functions have the requirements stated in
reference_feature.labels (dictionary, optional) – A dictionary with the labels for the new features. The keys are the feature function names and the values are a list of labels for each axis. The number of elements in the list corresponds to the dimension of the feature. Example:
new_labels = {"0d_feature": ["x-axis"], "1d_feature": ["x-axis", "y-axis"], "2d_feature": ["x-axis", "y-axis", "z-axis"] }
Raises: TypeError– Raises a TypeError if new_features is not callable or list of callables.Notes
The features added are not added to
features_to_run.features_to_runmust be set manually afterwards.See also
uncertainpy.features.Features.reference_feature()- reference_feature showing the requirements of a feature function.
-
calculate_all_features(*model_results)[source]¶ Calculate all implemented features.
Parameters: *model_results – Variable length argument list. Is the values that model.run()returns. By default it contains time and values, and then any number of optional info values.Returns: results – A dictionary where the keys are the feature names and the values are a dictionary with the time values time and feature results on values, on the form {"time": t, "values": U}.Return type: dictionary Raises: TypeError– If feature_name is a utility method.Notes
Checks that the feature returns two values.
See also
uncertainpy.features.Features.calculate_feature()- Method for calculating a single feature.
-
calculate_feature(feature_name, *preprocess_results)[source]¶ Calculate feature with feature_name.
Parameters: - feature_name (str) – Name of feature to calculate.
- *preprocess_results – The values returned by
preprocess. These values are sent as input arguments to each feature. By default preprocess returns the values thatmodel.run()returns, which contains time and values, and then any number of optional info values. The implemented features require that info is a single dictionary with the information stored as key-value pairs. Certain features require specific keys to be present.
Returns: - time ({None, numpy.nan, array_like}) – Time values, or equivalent, of the feature, if no time values returns None or numpy.nan.
- values (array_like) – The feature results, values must either be regular (have the same number of points for different paramaters) or be able to be interpolated.
Raises: TypeError– If feature_name is a utility method.See also
uncertainpy.models.Model.run()- The model run method
-
calculate_features(*model_results)[source]¶ Calculate all features in
features_to_run.Parameters: *model_results – Variable length argument list. Is the values that model.run()returns. By default it contains time and values, and then any number of optional info values.Returns: results – A dictionary where the keys are the feature names and the values are a dictionary with the time values time and feature results on values, on the form {"time": time, "values": values}.Return type: dictionary Raises: TypeError– If feature_name is a utility method.Notes
Checks that the feature returns two values.
See also
uncertainpy.features.Features.calculate_feature()- Method for calculating a single feature.
-
features_to_run¶ Which features to calculate uncertainties for.
Parameters: new_features_to_run ({“all”, None, str, list of feature names}) – Which features to calculate uncertainties for. If "all", the uncertainties are calculated for all implemented and assigned features. If None, or an empty list , no features are calculated. If str, only that feature is calculated. If list of feature names, all listed features are calculated. Default is"all".Returns: A list of features to calculate uncertainties for. Return type: list
-
implemented_features()[source]¶ Return a list of all callable methods in feature, that are not utility methods, does not starts with “_” and not a method of a general python object.
Returns: A list of all callable methods in feature, that are not utility methods. Return type: list
-
interpolate¶ Features that require an interpolation.
Which features are interpolated, meaning they have a varying number of time points between evaluations. An interpolation is performed on each interpolated feature to create regular results.
Parameters: new_interpolate ({None, “all”, str, list of feature names}) – If "all", all features are interpolated. If None, or an empty list, no features are interpolated. If str, only that feature is interpolated. If list of feature names, all listed features are interpolated. Default is None.Returns: A list of irregular features to be interpolated. Return type: list
-
labels¶ Labels for the axes of each feature, used when plotting.
Parameters: new_labels (dictionary) – A dictionary with key as the feature name and the value as a list of labels for each axis. The number of elements in the list corresponds to the dimension of the feature. Example:
new_labels = {"0d_feature": ["x-axis"], "1d_feature": ["x-axis", "y-axis"], "2d_feature": ["x-axis", "y-axis", "z-axis"] }
-
preprocess¶ Preprossesing of the time time and results values from the model, before the features are calculated.
No preprocessing is performed, and the direct model results are currently returned. If preprocessing is needed it should follow the below format.
Parameters: *model_results – Variable length argument list. Is the values that model.run()returns. By default it contains time and values, and then any number of optional info values.Returns: Returns any number of values that are sent to each feature. The values returned must compatible with the input arguments of all features. Return type: preprocess_results Notes
Perform a preprossesing of the model results before the results are sent to the calculation of each feature. It is used to perform common calculations that each feature needs to perform, to reduce the number of necessary calculations. The values returned must therefore be compatible with the input arguments to each features.
See also
uncertainpy.models.Model.run- The model run method
-
reference_feature(*preprocess_results)[source]¶ An example feature. Feature function have the following requirements.
Parameters: *preprocess_results – Variable length argument list. Is the values that Features.preprocessreturns. By defaultFeatures.preprocessreturns the same values asModel.runreturns.Returns: - time ({None, numpy.nan, array_like}) – Time values, or equivalent, of the feature, if no time values return None or numpy.nan.
- values (array_like) – The feature results, values must either be regular (have the same number of points for different paramaters) or be able to be interpolated. If there are no feature results return None or numpy.nan instead of values and that evaluation are disregarded.
See also
uncertainpy.features.Features.preprocess()- The features preprocess method.
uncertainpy.models.Model.run()- The model run method
uncertainpy.models.Model.postprocess()- The postprocessing method.
-
validate(feature_name, *feature_result)[source]¶ Validate the results from
calculate_feature.This method ensures each returns time, values.
Parameters: - model_results – Any type of model results returned by
run. - feature_name (str) – Name of the feature, to create better error messages.
Raises: ValueError– If the model result does not fit the requirements.TypeError– If the model result does not fit the requirements.
Notes
Tries to verify that at least, time and values are returned from
run.model_resultshould follow the format:return time, values, info_1, info_2, .... Where:time_feature:{None, numpy.nan, array_like}Time values, or equivalent, of the feature, if no time values return None or numpy.nan.
values:{None, numpy.nan, array_like}The feature results, values must either be regular (have the same number of points for different paramaters) or be able to be interpolated. If there are no feature results return None or
numpy.naninstead of values and that evaluation are disregarded.
- model_results – Any type of model results returned by